
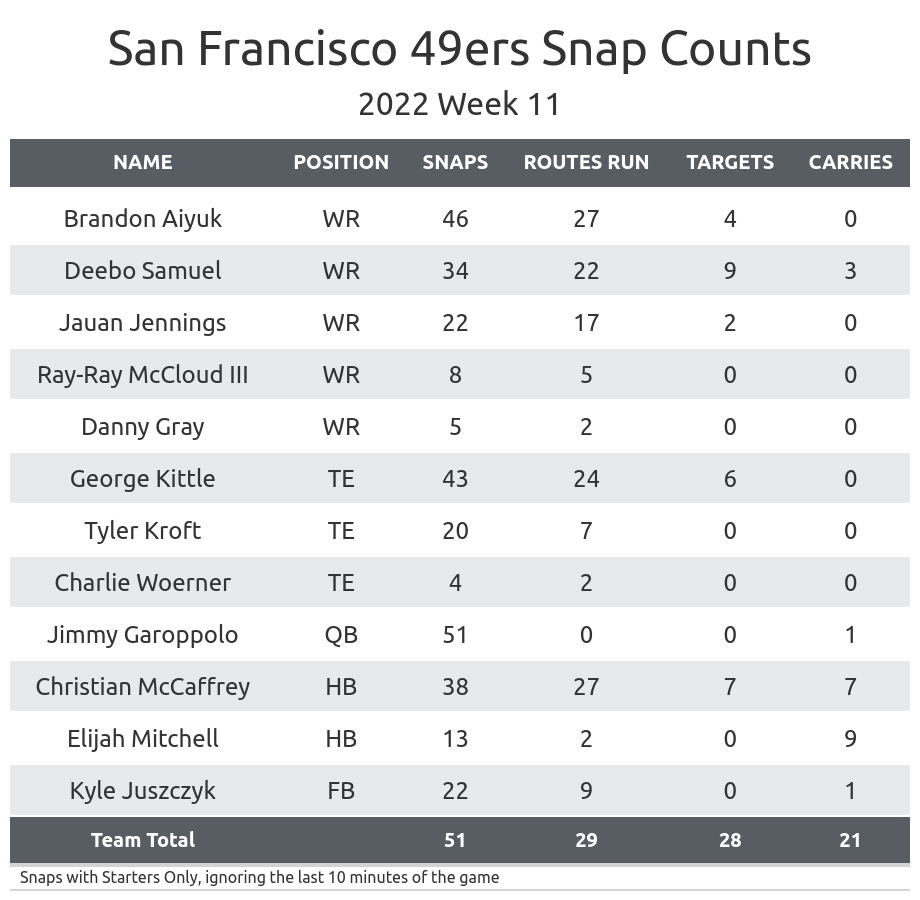
Okay, so yesterday I was messing around trying to grab some player stats from the 49ers vs. Arizona Cardinals game. Sounded simple enough, right? Man, I was wrong.

First, I thought, “I’ll just Google it!” Found a bunch of sites, but all of them were either trying to sell me something or had stats all jumbled up. Super annoying. So, I figured I’d try to do it myself, like a real data guy, you know?
Started with trying to scrape ESPN’s website. I’ve done that before, and it’s usually not too bad. But their HTML is a mess! Tables nested inside tables, divs all over the place. I spent a good hour just trying to figure out which elements had the actual player stats I needed. Used BeautifulSoup in Python, of course. That thing is a lifesaver.
Got some data, but it was super dirty. Player names were inconsistent, some stats were missing, and the whole thing was just a pain to clean. I tried using Pandas to wrangle it, but it was still a mess. Spent another couple of hours just cleaning and formatting the data. I even had to manually correct some player names. Ugh.
Then, I thought, maybe there’s an API I can use. Started digging around and found a few that looked promising. One was charging an arm and a leg, and another was just completely broken. Finally, I found one that seemed legit. Scored! But then, bam! Rate limits. Could only make like, 10 requests a minute. At this point, I was ready to throw my laptop out the window.
So, I did what any sane person would do. I took a break, grabbed a beer, and watched some YouTube. Came back later and decided to try a different approach. Instead of scraping the whole page, I focused on just the tables with the player stats. Wrote some custom CSS selectors to target those specific elements. It actually worked pretty well! Still had to do some cleaning, but it was way faster than before.
Finally got something that looked decent. I ended up with a CSV file with the player names, passing yards, rushing yards, touchdowns, all that good stuff. It’s not perfect, but it’s good enough for what I wanted to do. I think next time I’ll just pay for a decent API. My time is worth something, right?
Lessons learned:
- Web scraping is always harder than you think.
- Cleaning data is the worst part of the job.
- APIs are great, but watch out for rate limits.
- Sometimes, you just need a beer break.
Next Steps
I’m thinking of trying to build a little dashboard to visualize the stats. Maybe using Plotly or something. I also want to see if I can automate the whole process so I don’t have to manually scrape the data every time. That would be pretty sweet.













{kind=link}