
Okay, so today I’m gonna walk you through my little project: “giron prediction.” It’s nothing fancy, just me messing around with some data and trying to predict stuff.

First things first, I grabbed the data. Found a dataset online, some CSV file, can’t remember exactly where, but it had all the info I needed. I think it was from Kaggle. Then, I fired up my Jupyter Notebook. Gotta love those notebooks, right?
Next, I imported all the usual suspects: pandas, numpy, scikit-learn. You know, the gang. Loaded the CSV into a pandas DataFrame. Always gotta check the head and tail, make sure everything looks okay. No weird characters or missing values in the first few rows.
Then comes the fun part: cleaning the data. There were some missing values, so I filled them with the mean or median, depending on the column. Also had to convert some categorical features into numerical ones. One-hot encoding to the rescue! Manually dropped some columns that I figured wouldn’t be useful for the prediction. Like IDs or something.
After cleaning, I split the data into training and testing sets. 80/20 split, standard stuff. Then, I tried a few different models. Started with Linear Regression, because why not? Then moved on to Random Forest, because everyone loves Random Forest. Also gave XGBoost a shot, because I heard it’s good. Nothing too fancy, just the default parameters for now.
To train these models, I used the fit() function. Simple enough. For each model, I calculated the predictions on the test set, and then calculated some metrics, like Mean Squared Error and R-squared. Just to see how well they performed. I will say it was looking pretty okay-ish.
After the basic models, I decided to get a little fancier. Tried some hyperparameter tuning using GridSearchCV. Defined a grid of parameters to try for each model, and let GridSearchCV do its thing. Took a while to run, but it was worth it. The models definitely improved after tuning.
Once I had my best model, I saved it to a file using pickle. Just in case I wanted to use it later without having to retrain it. Then, I wrote a small script to load the model and make predictions on new data. Really simple input with prints, just enough to prove it works.
And that’s pretty much it! “giron prediction” in a nutshell. It’s not perfect, and there’s definitely room for improvement, but it was a fun little project to work on. I learned a lot, and that’s what matters.
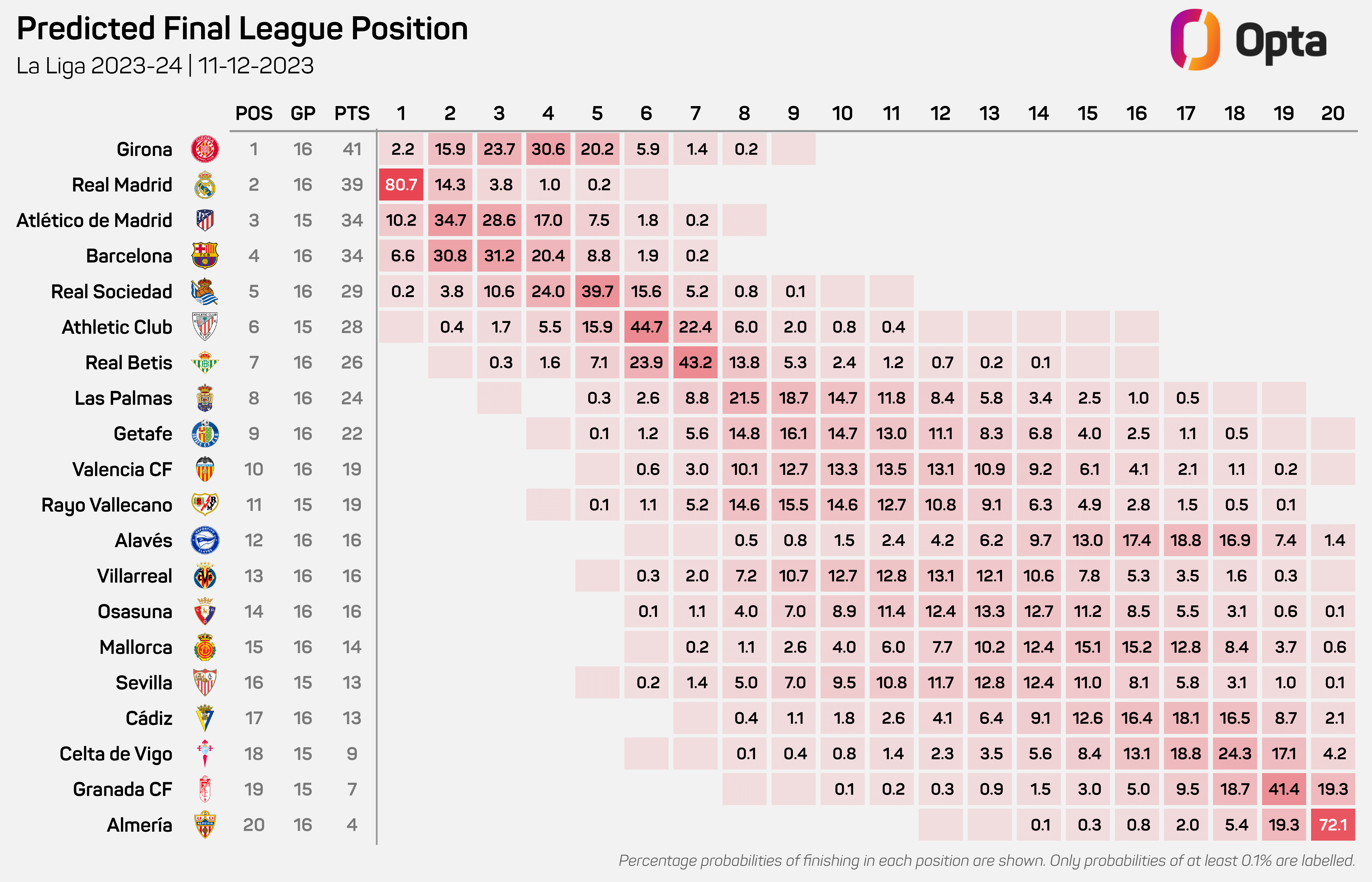
- Data Collection: I started by gathering the necessary data.
- Data Cleaning: I handled missing values and converted categorical features.
- Model Training: I experimented with Linear Regression, Random Forest, and XGBoost.
- Hyperparameter Tuning: I used GridSearchCV to optimize model parameters.
- Model Deployment: I saved the best model and created a script for making predictions.
Would love to explore something else next! Maybe a more complicated problem, or maybe try out a different type of model.















{kind=link}